Portfolio Chatbot: Agentic RAG over My Background
Personal Project · 2025 · GitHub
Overview
This is the chatbot you can interact with on my portfolio site. It can answer questions about my background, projects, skills, and experience at zero cost. The goal was to build a genuinely useful assistant without relying on paid APIs for the language model itself, and to do it in a way that is transparent, observable, and architecturally interesting.
Skills Based Architecture
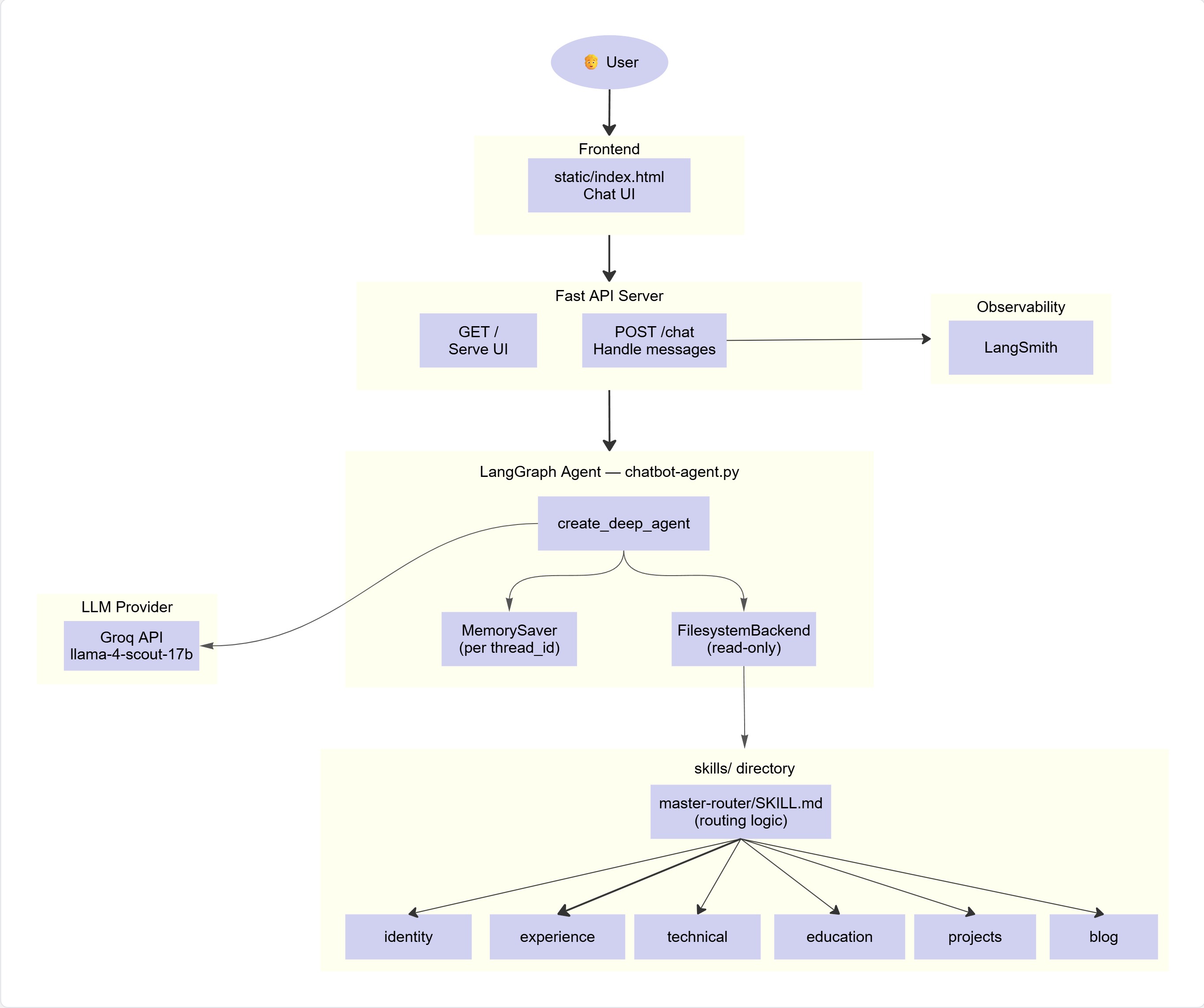
Rather than dumping all information into a single large context, the chatbot uses a skills based routing approach. Each skill is a self-contained Markdown file, one for my identity, one for my work experience, one for my projects, one for my technical background, one for my education, and one for my blog.
A dedicated master-router skill reads the user's message and decides which skill is relevant before any content is loaded. The model only receives the descriptions of available skills in its system prompt, not the full content. When a user asks a question, the router decides which skill to load at runtime, injecting only the relevant knowledge into the context. This keeps the context lean and makes it easy to add or update knowledge without touching the core agent logic.
Agent Orchestration
The agent is built with LangGraph using the DeepAgents framework, which manages the conversation flow as a stateful graph. Conversation memory is maintained per session using LangGraph's MemorySaver, keyed by thread_id, so the agent remembers context across turns in the same conversation. Skill files are accessed via a virtual read-only FilesystemBackend. The graph handles:
- Receiving the user's message and current conversation state
- Routing to the appropriate skill via the master-router
- Loading the relevant skill and injecting its content
- Generating a response with the enriched context
Model & Inference
The language model is llama-4-scout-17b an open-source model served through Groq, which provides fast inference at no cost within their free tier. One side effect of this is a noticeable delay on the very first question: Groq loads the model on first request, which introduces a cold-start latency. Subsequent questions in the same session are much faster.
Observability
LangSmith is wired into the pipeline for full observability, every agent step, skill lookup, and LLM call is traced. This makes it easy to inspect what the model decided to do and why, which is especially useful for catching cases where the wrong skill is loaded or the routing logic misfires.
Deployment Architecture
The portfolio is a static site hosted on GitHub Pages, which means there is no server-side code. To support the chatbot, a separate backend was built, a FastAPI service (main.py) deployed on Render, exposing two endpoints: GET / to serve the chat UI and POST /chat to handle messages. When a message is typed in the chat widget, the static frontend sends a request to the Render backend, which runs the LangGraph agent, calls Groq, and returns the response.
This split architecture keeps the portfolio fully static and cheap to host while allowing the agent backend to scale independently.
Tech Stack
LangGraph · LangSmith · Groq · FastAPI · Python · Render · GitHub Pages